RSNNs with SNNTorch (unfinished)
Scroll down or use the arrow keys to move through the slides.
Last training run 5/12/2025, 5:56:52 PM
Moving MNIST
A dataset of moving digits.

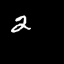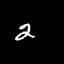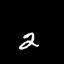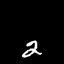
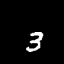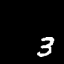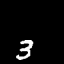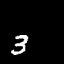

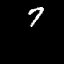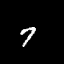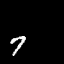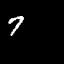


The Network
The network is a Recurrent Spiking Neural Network (RSNN) built with the snntorch library.
It uses recurrent leaky integrate-and-fire (RLeaky) spiking neurons and consists of two fully
connected spiking layers.
nn.Flatten(start_dim=1)Converts 2D image frames into 1D vectors so they can be fed into dense layers.nn.Linear(input_size, hidden_size)Projects raw input features into a high-dimensional hidden space for richer representations.nn.Dropout(p)Randomly zeroes some hidden activations during training to improve generalization.snn.RLeaky(...)Adds temporal spiking dynamics and memory to the hidden representation using recurrent leaky integrate-and-fire neurons.nn.Linear(hidden_size, output_size)Translates hidden spike patterns into class-specific features.snn.RLeaky(...)Accumulates spikes over time in the output layer to drive final class predictions.
The forward method flattens the input, passes it through the linear layer, dropout, and the first recurrent spiking layer to produce hidden spikes. These are then passed through another linear layer and spiking layer to produce output spikes, which are used downstream for classification.
import torch
import torch.nn as nn
import snntorch as snn
class RSNNNet(nn.Module):
def __init__(self, hp, input_size: int):
super().__init__()
self.flatten = nn.Flatten(start_dim=1)
self.fc1 = nn.Linear(input_size, hp.hidden_size, bias=True)
# self.dropout1 = nn.Dropout(hp.dropout_p)
self.snn1 = snn.RLeaky(beta=hp.beta,
spike_grad=hp.spike_grad,
init_hidden=True,
all_to_all=True,
linear_features=hp.hidden_size
)
self.fc2 = nn.Linear(hp.hidden_size, hp.output_size, bias=True)
self.snn2 = snn.RLeaky(beta=hp.beta,
spike_grad=hp.spike_grad,
init_hidden=True,
all_to_all=True,
linear_features=hp.output_size
)
def forward(self, x: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
x = self.flatten(x)
x = self.fc1(x)
# x = self.dropout1(x)
spk1 = self.snn1(x)
x = self.fc2(spk1)
spk2 = self.snn2(x)
return spk1, spk2Training Results
Spike Rasters
Spike Rasters: Hidden Layer during evaluation
Spike Rasters: Output Layer during evaluation
Weights
View the weights and biases for each layer before and after training.